
Making Biostarks an AI native at-home biomarker testing company
This is the first in a series of articles on how we are designing and operating Biostarks in the age of AI. Not a manifesto — a working account of what we are actually building.
When we completed the acquisition of Biostarks in summer 2025, AI for the organisation meant mostly running a GPT prompt before reviewing emails. Not because the team wasn't capable of more — they were — but because the foundation hadn't been set and the culture hadn't been pushing for it. That has since changed substantially. This article is an honest account of how we are rebuilding Biostarks as a genuinely AI-native at-home biomarker testing company: what that looks like in practice, what it demands from a team, and where it is taking us.
The architecture diagram that accompanies this piece was generated entirely within a Notion document, without human intervention. Consider that a small signal of what follows.

Table of contents
- Internal facing: Knowledge, Collaboration and Orchestration layer
- External facing: the Agentic Product Layer
- In between, the Data layer: authority file and back office
- Culture and what's next
1. Internal facing: Knowledge, Collaboration and Orchestration Layer
This layer serves internal tooling and processes. It is powered by Slack, Notion and Claude, and the way those three interact is what makes it worth writing about.
Slack is the obvious choice for collaboration — though we consistently find more interoperability there than with alternatives. It is where signals live: decisions surfaced in threads, follow-ups buried in replies, product intuitions typed at 11pm and forgotten by morning.
Notion is a longer story. It entered the picture in 2019 — first as a note-taking tool at INSEAD, then as a surface for writing option contract chains — and it has since become the entire intelligence and knowledge repository for Biostarks. It houses accounts, projects, documents (from contracts to SOPs), functions, agents, tasks, and more. But describing Notion as a knowledge base undersells it. The more accurate description is a relational operating system: a single task can be simultaneously linked to the account it relates to, the project it sits within, the document it references, and the function responsible for it. That multi-relational structure is what makes Claude's skills genuinely useful rather than just a smarter search layer — when Claude surfaces context, it surfaces connected context. Most companies use Notion as a wiki. We use it as the connective tissue of the business. If Slack is where we think out loud, Notion is where we think clearly.
Claude (by Anthropic) is the third component of this layer, and the one that ties the other two together. It is also the hardest to describe in a single sentence, because it is doing several genuinely different things at once — and doing them well enough that we think of it less as a tool and more as the operating environment for how the company thinks and acts, including with third-parties using MCPs.
💡 On MCP. The Model Context Protocol is an open standard by Anthropic — a universal adapter that lets any AI system query any data source through a consistent interface, in natural language, without custom plumbing. Write the server once; any MCP-compatible model can use it.
Claude as a Skills layer. The first and most structurally important thing Claude does at Biostarks is act as an intelligent interface over the company's data and systems — through what Claude calls Skills. A Skill is a packaged set of instructions and context that tells Claude how to behave, what it can access, and how to interact with a particular domain or workflow. In their simplest form, Skills are reusable system-level configurations — a way of giving Claude a persistent, well-defined role without rebuilding the context each time. In more complex implementations, they can serve as abstraction layers over external systems: wrapping an MCP server or API so that Claude can query structured data in natural language, on behalf of a user, without that user needing to know what is underneath.
Two of our Skills are of that second kind. Task-operator wraps an MCP connection to Biostarks' Task database in Notion — allowing any team member to query, create, update and close tasks conversationally, with full awareness of status, priority, assignee and project relationships. "What are the open P0s assigned to Manu?" resolves instantly, without opening Notion. Such skills also provides guiding principles for more complex AI agents to manage tasks as a sub-part of their large mandate (e.g. first scooting for information in chats, then create tasks out of it, following the principles established by the task-operator skill).
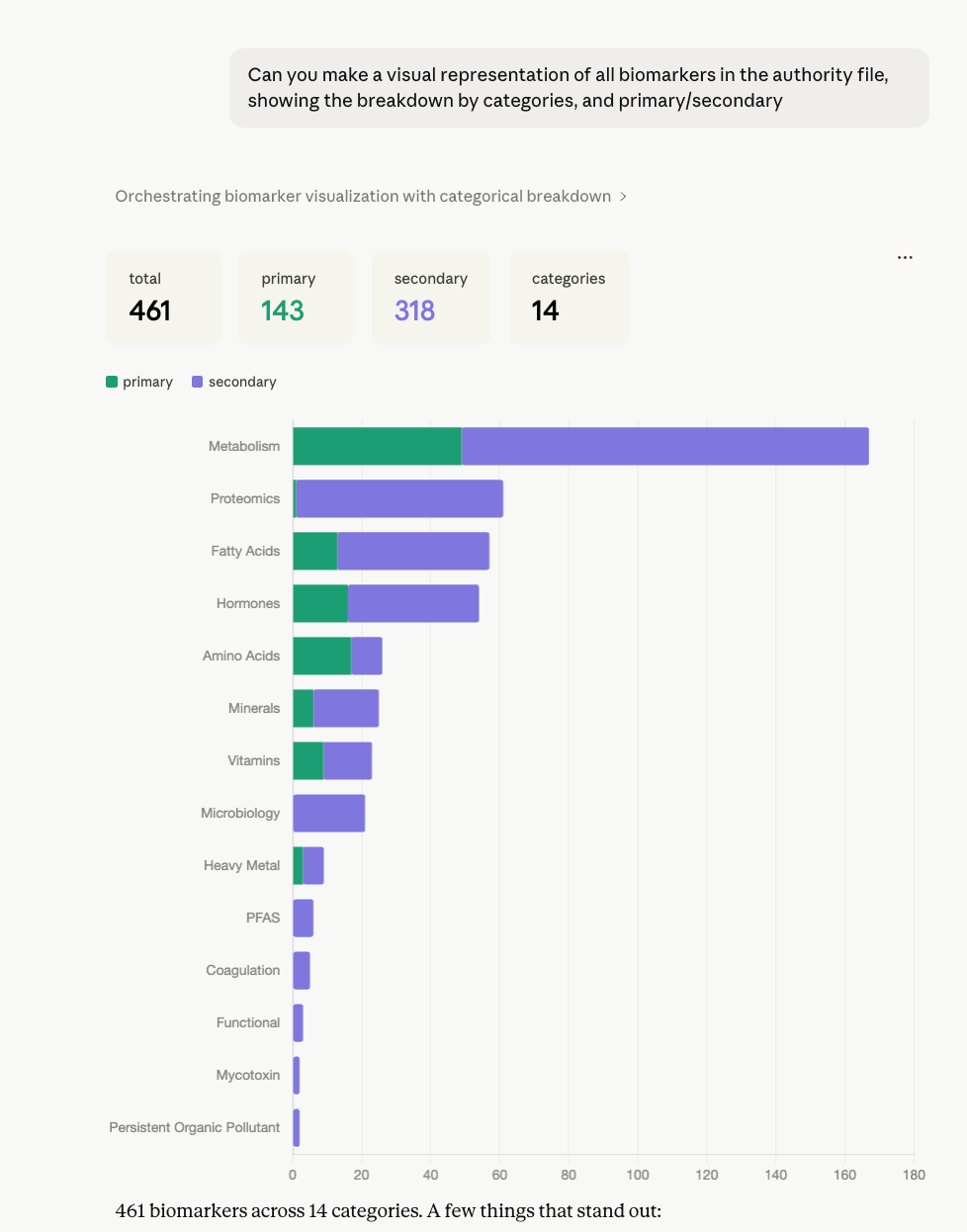
Biomarkers-explorer wraps an MCP connection to the authority file on Elasticsearch — 500+ manually reviewed biomarkers across 20+ classes — allowing the team to explore coverage, compare entries, check stratified ranges, and build research hypotheses entirely in conversation. A functional team member asking "show me all biomarkers in the hormonal category with a serum matrix that don't yet have stratified ranges" gets a precise, actionable answer without writing a single query. Every Skill of this kind has expanded the surface area of questions a non-technical team member can answer themselves, without a ticket to engineering.
Both of these are also the foundation for the authority file enrichment workflow — the most governed use of Skills in the stack. When a new biomarker needs to be proposed, the entire workflow runs inside Claude: draft the entry, validate against the existing schema, run the propose → confirm → commit sequence with peer review and a logged Slack notification to #undisclosed-channel. The authority file does not drift. Every change is traceable. The person committing the change spent their cognitive effort on the science, not on navigating a database.
This pattern — a scoped MCP server, a governed workflow, Claude as the interface — is also why external biomedical MCP servers like BioMCP are genuinely interesting to us.
Claude as agent supervisor. The second role of Claude is to manage supervised agents, starting with Babou family — a set of persistent, scoped agents running via Claude's CoWork environment, each with a defined remit and level of autonomy.
Babou.epsilon is our strategic early-warning system. It continuously scans internal conversations for ideas, gaps, and anomalies that are worth capturing but not yet actionable — and logs them as Signals in Notion. Unlike tasks, Signals have no owner and no deadline. They are observations that deserve attention before anyone has decided what to do with them.
Babou.iota is our quality assurance hire. It seeks data quality gaps across instances and collects product discovery feedback from users — a kind of always-on researcher with no patience for noise.
Babou.omicron supervises the other agents, runs health checks, and escalates when something looks off.
Together, they are progressively turning Claude into what we now internally call an agentic powerhouse.
Finally, Claude as a multi-modal hub. The third role is more diffuse but arguably the most important day-to-day. Claude is where the team operates: writing, editing, researching, drafting investor communications, scoping technical proposals, reviewing SOPs, querying the CRM, checking biomarker coverage before a partner call. The Skills layer means these interactions are context-aware — Claude knows what Biostarks actually is, what's in the roadmap, who owns which account, what the authority file contains. The result is that work which previously required either a context-loaded team member or a sequence of tool-switching happens in a single, continuous session. We have found this particularly significant for tasks that sit at the intersection of domains — a partner pitch that requires knowing both the commercial account history and the relevant biomarker panel coverage, for instance. That kind of synthesis used to require a meeting. Now it takes a prompt.
Taken together — Skills, managed agents, operational hub — Claude has become the connective tissue of the internal organisation. The phrase we use internally is agentic powerhouse.
2. External facing: the Agentic Product Layer
This layer serves customer, patient and HCP-facing features. It runs primarily on the OpenAI platform, where the depth of available models allows for fit-for-purpose agentic design and meaningful control over unit economics. These are not generic AI features bolted onto a product — they are a pipeline of agent building the product.
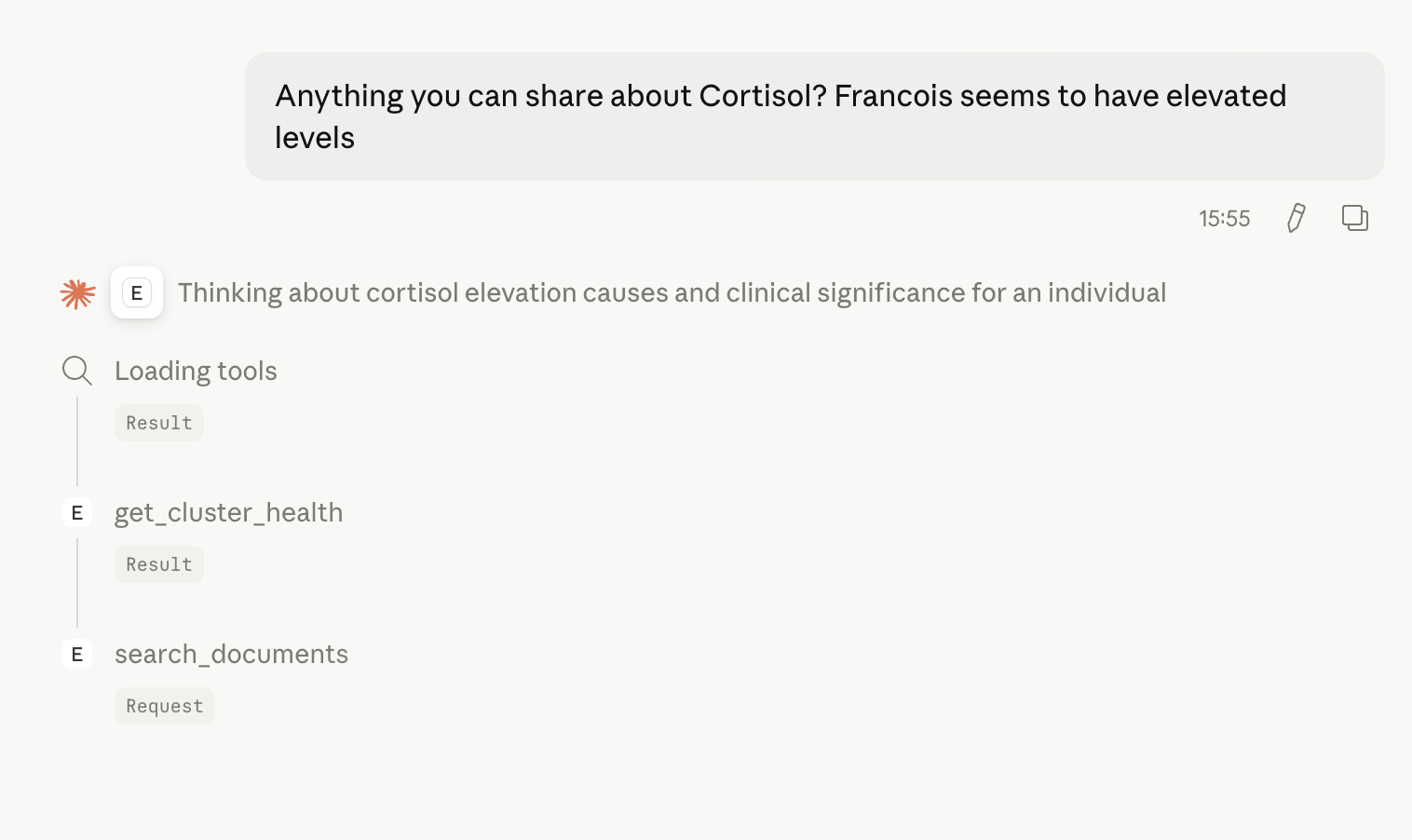
Maurice was the first to arrive. He takes structured lab input and turns it into personalised recommendations and protocols. He oversees insight extraction, identifies physiological clusters, and extracts knowledge concepts. He is not lazy about context: Maurice enriches himself from longitudinal results for each client, as well as from contextual information — supplementation history, active protocols such as TRT or GLP-1 — and where available, medical records and genomic reports. The protocol awareness matters more than it might sound. A testosterone result that appears borderline low reads entirely differently in the context of an active TRT protocol — Maurice understands that, and so do the HCPs reviewing the output. It is the difference between an alert and an insight. NPS from both consumers and practitioners on how Maurice makes large datasets digestible has been consistently strong, and protocol-aware interpretation is consistently what gets mentioned. That is the right metric to watch.

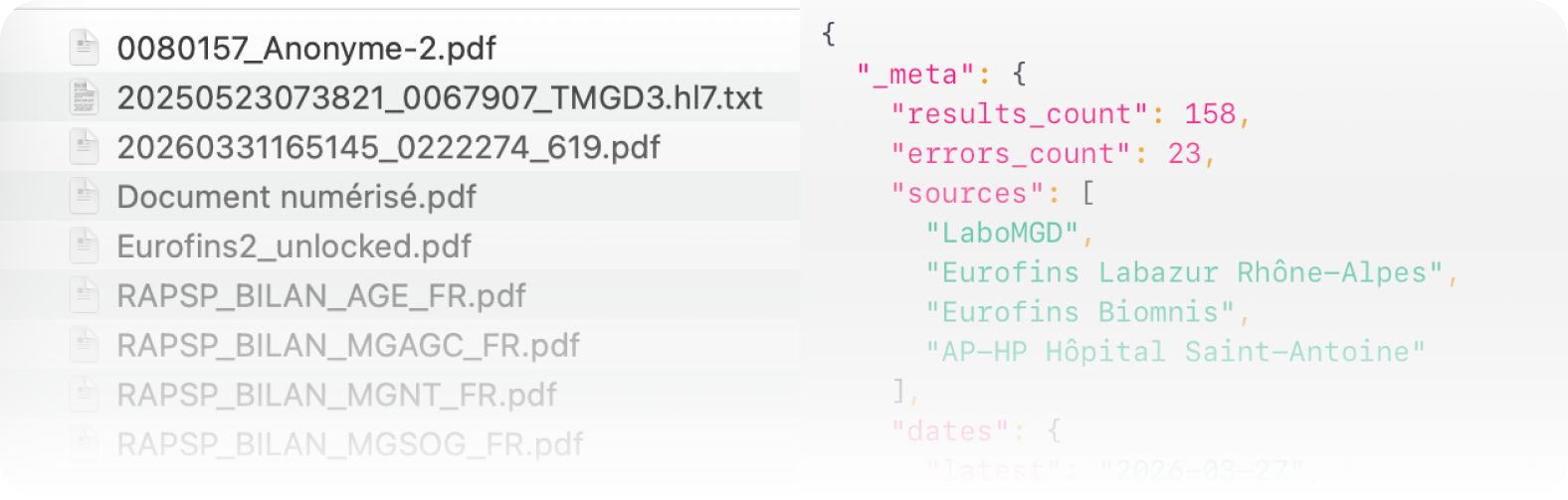
Henri handles the translation layer. He takes semi-structured inputs — HL7 files, PDF lab reports across multiple languages and formats — and turns them into structured data that Maurice can work with. Henri connects directly into the authority file (more on that below), which gives him a precise vocabulary of 500+ reviewed biomarkers to work against. Without Henri, Maurice would be brilliant but occasionally confused. With him, the pipeline becomes reliable.
Finally, Clyde ensures that outputs reach people in their own language. Three locales today, thirteen planned for this summer.
In the pipeline: Jane, who structures biomarker maps for large reports with no predetermined structure; and Jarvis, who takes time-series data from connected services like Withings or Oura and turns it into pre-structured, insight-rich artefacts for Maurice to work from.
The naming is deliberate. We have found that giving agents distinct identities — rather than calling them "module A" and "pipeline B" — changes how the team thinks and communicates about them. They are part of the team.
It creates accountability in a system that could otherwise feel opaque.
3. In between: the Data Layer
Two components, distinct roles.
The authority file is the single source of truth for every biomarker Biostarks covers — currently 500+ entries across 20+ classes, all manually reviewed. It runs on Elasticsearch. Every entry contains reference ranges, stratified ranges by gender and age, interpretation guidelines (you would likely not know what to do with your hpg80 levels unaided), literature sources and domain mappings.
It also includes something less obvious but arguably more important: an identity mechanism for disambiguation. A naive approach to parsing lab reports — OCR the PDF, extract the names, match them — fails in production because laboratory nomenclature is inconsistently standardised. The same analyte appears under different names, acronyms, and fractionation descriptors depending on the lab, the country, and the instrument used. When Henri extracts multiple valid candidates from a PDF — Folate Serum versus B9 erythrocyte, for instance, which are related but clinically distinct — the authority file is what resolves the ambiguity correctly rather than defaulting to the first plausible match. This matters because a wrong match upstream produces a wrong interpretation downstream, and in a health context that is not a minor inconvenience. The identity mechanism is one of the things that makes the pipeline trustworthy, not just functional.
Claude has a skill.md that provides a GUI over the authority file, allowing functional team members to explore, build hypotheses and understand coverage without touching a database. Chat-originated enrichment from the Claude console is also possible, following a strict propose → confirm → commit workflow, with peer review and logged commits. The authority file does not drift — every change is traceable.
The back office. At its core it is a Symfony-based backend — the historical engineering layer that predates everything else in this article. But describing it as "the old system" would be wrong, because it has been actively extended into the connective tissue of the entire AI stack. It now plays four distinct roles simultaneously, and the tension between those roles is actually part of what makes the architecture interesting.
The first role is kit lifecycle management. Every dry blood spot kit that Biostarks dispatches has a lifecycle — created, shipped, delivered, returned by the patient, received by the lab, processed, results uploaded. Each of these transitions is a typed event in the back office's event-driven architecture. The payload structure is deliberate: every event carries a source, a timestamp, a unique ID, and a structured data block that includes partner account metadata, kit IDs, order details, and any relevant flags. When a kit reaches RECEIVED or RESULTS_UPLOADED status, the back office fires the appropriate downstream actions — email notifications to the consumer or practitioner, Slack pings to the relevant internal channel, and in B2B deployments where a partner has a shared Slack workspace, a notification there too. The event schema was designed to be extended: adding a new partner, a new notification channel, or a new status trigger does not require surgery on the core system. It requires adding a handler.
The second role is partner API operator. Biostarks' B2B model requires that partners — wellness platforms, supplement brands, health insurers — can integrate our testing pipeline into their own products without building custom extraction logic. The back office exposes a public Partner API and an internal Service API that handle order creation, kit assignment, result retrieval, and account provisioning. The metadata layer in the order payload is what allows a B2B order from a partner like Lifesum or Aveva to carry its own channel attribution, kit batch, VIP flags, and partner account linkage — all of which flow through into reporting and into how results are routed downstream. The back office knows which customer belongs to which partner, and that knowledge propagates correctly.
The third role — and the most recent addition — is AI agent orchestrator. The processing pipeline agents (Maurice, Henri, Clyde and those in development) do not float freely in the OpenAI platform. They are invoked, sequenced, and monitored through the back office. System prompts are versioned and stored there, making the back office the single source of truth for what each agent is actually told to do at any given moment. The OpenAI platform dashboard serves as a playground for development; the back office is what runs in production. This matters because it means agent behaviour is governed by the same versioning and deployment discipline as the rest of the codebase — not by whoever last edited a prompt in a UI.
The fourth role is ERP and operational backbone, covering the parts of the business that Notion does not yet handle: financial transactions, kit inventory, lab partner integrations, logistics handoffs. Not glamorous, but load-bearing.
What is worth flagging about this architecture is what it implies for the relationship between the back office and the AI layer above it. The processing agents are effectively stateless — they receive a payload, run their logic, and return an output. The back office is what provides the state: the kit history, the patient longitudinal record, the partner context, the system prompt version. Maurice can be brilliant precisely because the back office ensures he always receives a well-formed, complete picture of the situation. The intelligence is distributed; the ground truth lives in one place.
This also means that when something goes wrong — a Henri extraction that produces an ambiguous match, a Maurice output flagged for review — the back office has the full audit trail. Every agent invocation, every input payload, every output is logged. That is not a nice-to-have in a regulated health context. It is the condition of trust.
4. Culture and what's next
There is a version of this section that reads like a change management memo — frameworks, maturity models, adoption curves. That is not the version that reflects what actually happened at Biostarks. What happened was messier and, in retrospect, more interesting.
Culture didn't shift because leadership mandated it. It shifted because the infrastructure made it easy to try things, and trying things produced results that spoke for themselves. When Babou.rho started surfacing tasks from Slack threads that team members had already half-forgotten, the argument for AI-native tooling didn't need to be made again. It had been made by the system.
That said, there are a few principles that have shaped how we think about this — and that we would hold up as deliberate, not accidental.
AI as infrastructure, not automation. The distinction matters. Automation is about replacing a task. Infrastructure is about expanding what is possible. A startup that thinks about AI as automation will use it to do the same things with fewer people. A startup that thinks about it as infrastructure will use it to do things that weren't previously possible with any number of people — and that is a fundamentally different bet. We are making the second bet.
Composing the system, not just running it. A framing that has stuck with us: the shift in leadership in an AI-native organisation is less like being a conductor — coordinating people in real time — and more like being a composer. The conductor ensures the orchestra plays together tonight. The composer decides what the music is, what principles govern how the parts relate, what the architecture sounds like. In practice, this means that the most important decisions we make are not operational — they are about how we design the agents, what the authority file contains, what Babou is allowed to do autonomously versus what requires a human. The system executes. We design the system.
Asymmetric leverage is the startup thesis. The honest competitive advantage that AI gives a small, ambitious company is not efficiency — it is clock cycles. Agents do not sleep. A GTM agent prospecting B2B accounts at 3am, a quality agent filing a data issue at 2am, a reporting agent that has already summarised the week before Monday morning starts — these are not marginal gains. For a team of our size competing in a market where most players are significantly better resourced, the ability to run around the clock without scaling headcount is a structurally different kind of leverage. The WEF noted in early 2025 that AI-native startups are achieving product-market fit with smaller teams and higher automation. That is the direction we are building toward — not as a cost measure, but as a competitive posture.
This is also why we think seriously about the long-run composition of the organisation. Our working hypothesis is that Biostarks — at meaningful scale — will operate roughly half with human team members and half with agents working alongside them. Not agents as tools that humans prompt. Agents as participants: accountable, scoped, supervised, but genuinely doing work. The humans will focus on judgment, relationships, creativity, and the design of the systems the agents run within. That is a different kind of organisation than what most companies are building toward, and we think it is the right one for what we are trying to do.
What that looks like concretely. On the internal orchestration layer, the Babou family is growing. A GTM agent for B2B prospection is next — scouting signals across our CRM, enriching account context, and drafting first-touch outreach without waiting for a sales rep to have a clear hour. A dedicated customer support interface is in scope: structured, Biostarks-knowledge-grounded, able to triage and resolve a significant share of inbound queries without human escalation. On the product side, a conversational agent is in development — allowing users to interact directly with their biomarker data, ask questions about their results, and receive contextualised guidance that goes beyond static report outputs. Each of these is an extension of the same logic: scope the agent clearly, connect it to the right data, supervise it properly, and let it run.
The harder cultural shift — and the one that is still ongoing — is the one around trust and accountability. Building a culture where team members feel genuinely empowered by AI tools rather than unsettled by them requires transparency about how the systems arrive at their outputs, and clear communication from leadership that agents are there to augment human work, not to redefine who belongs. That communication has to be consistent, and it has to be backed by how decisions are actually made day to day. We are still earning that consistency.
AI-native organisations are defined not by their technology stacks, but by their coherence — clear decision rights, minimal bureaucracy, explicit norms governing human-agent interaction, and strong accountability for outcomes. That is an accurate description of what we are building toward. We are not there yet in every dimension. But the architecture is set, the direction is clear, and the compounding has started.
More updates to follow as we build.
What changed between summer 2025 and today was not the team's capability — that was always there. What changed was the foundation: structured knowledge, connected tooling, and a shared belief that AI is not a shortcut but an infrastructure choice. Every agent we deploy, every enrichment we commit to the authority file, every Babou report that surfaces a task before we knew to look for it — these are compounding bets on that belief.
— Romain Dorange, CEO & Co-Founder, Biostarks